







Staff Augmentation
Access top-tier talent on demand: Dedicated, Hourly, or Flexible.






























 Copy Link
Copy Link Share on X
Share on X Share on Facebook
Share on Facebook Share on LinkedIn
Share on LinkedIn
When ChatGPT first excited the leadership team, the possibilities for enterprise AI seemed endless! However, as the excitement fades, reality hits: your AI initiatives are running into tough challenges. Hallucinations in business decisions, outdated information, no access to proprietary knowledge. Yes, Gen AI tools are good for general tasks, but they are not built for a complex enterprise world.
Here, Retrieval-Augmented Generation (RAG) comes in, which promises to ground AI responses in your company’s own data. However, for many organizations, even traditional RAG solutions are not enough.
Besides that, enterprises deploying traditional Retrieval Augmented Generation (RAG) models report persistent issues with data accuracy, hallucinations, and integration gaps across siloed information sources.
The result? Billions wasted annually on underperforming AI implementations. Yes, these models enhance reasoning capabilities, but they come at a price (financial and latency cost).
For example, according to Open AI, GPT-4o costs $2.50 per 1 million input tokens and $10 per 1 million output tokens. The o1 costs $15 per 1 million input tokens and $60 per 1 million output tokens.
Indeed, traditional RAG architectures, while promising, often fail to deliver enterprise-grade accuracy. In fact, a recent IDC survey found that large organizations cite “fragmented knowledge bases” as the top barrier to effective AI adoption.
However, there is a way to unlock the true potential of your business data. That is why enterprises like JP Morgan and IBM are using Hybrid RAG Architecture for niche processes. It seamlessly combines the semantic understanding of vector search with the reliability of structured knowledge graphs.
In this blog, we are going to explore how Hybrid RAG Architecture can transform your enterprise AI strategy. You will discover the technical foundations that make it work, real-world implementations across industries, and practical steps to evaluate whether this technology fits your organization’s needs. So, let’s dive in:
Key Takeaways
- Hybrid RAG architecture combines vector search semantic understanding with structured knowledge graphs.
- Unlike static models, Hybrid RAG integrates the latest business information, crucial for dynamic industries.
- It provides traceable, source-linked responses with audit trails, which is crucial for regulated industries like healthcare and finance.
- Dynamic orchestration, parallel processing, and modular architecture handle massive datasets while maintaining fast response times.
- Early adopters gain a competitive advantage through faster insights and reduced operational costs.

What is Hybrid RAG Architecture?
Hybrid RAG Architecture is an advanced framework in artificial intelligence. It combines multiple retrieval techniques (vector-based search and structured knowledge graphs) to enhance the accuracy of generative AI outputs.
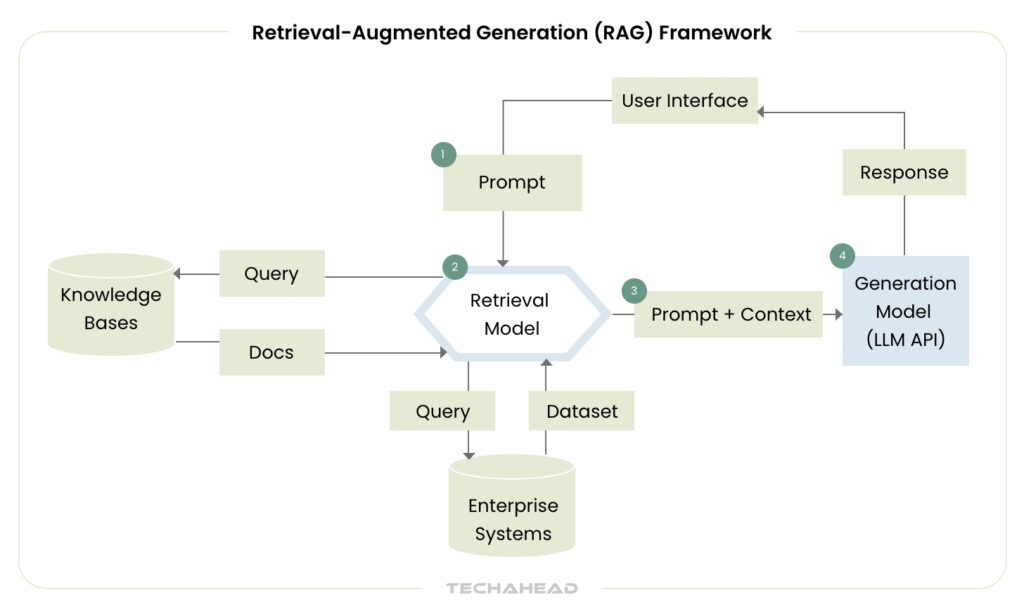
Traditional language models usually rely on pre-trained knowledge. However, hybrid RAG dynamically retrieves both unstructured and structured data at the time of a user query.
It means that when you ask a question, the system searches across diverse data sources, which merges the most relevant information and generates context-aware responses. As a result, you can expect ‘personalized’ responses suitable for your enterprise needs.
How Does Hybrid RAG Differ from Simple RAG?
Hybrid RAG is the advanced form of simple RAG that addresses the challenges more efficiently and helps your enterprise get better responses. Following table shows the key differences between the two models:
| Feature | Simple RAG | Hybrid RAG |
| Retrieval Method | Single (usually vector or keyword) | Combines multiple (vector, keyword, graph, etc.) |
| Data Types Supported | Unstructured text only | Structured and unstructured data |
| Context Handling | Independent text chunks | Merges structured and unstructured context |
| Accuracy & Robustness | Moderate, can miss nuanced queries | Higher, handles complex and ambiguous queries better |
| Scalability | Easier to deploy, less resource intensive | More complex setup, suited for enterprise environments |
| Use Cases | FAQs, basic Q&A, simple summarization | Financial analysis, compliance, multi-domain reasoning |
| Hallucination Risk | Higher, limited grounding | Lower, better factual grounding |
Key Components of Hybrid RAG Systems
Now, you may ask what makes Hybrid RAG so powerful compared to traditional AI solutions? The answer lies in its multi-layered architecture that seamlessly orchestrates data retrieval, processing, and generation.
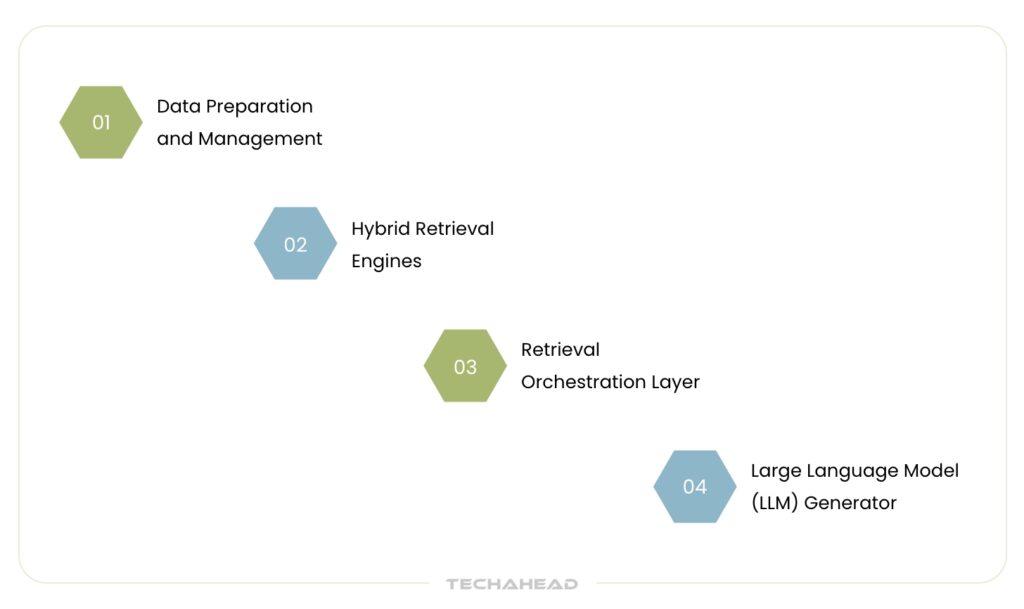
Data Preparation and Management
Data ingestions and processes are essential parts of data management. Generally, enterprise data is divided into manageable segments (chunks) and transformed into vector embeddings using advanced embedding models.
Moreover, effective data management includes generating metadata and summaries (for quick retrieval) and data cleaning for indexing relevant, high-quality business information.
Hybrid Retrieval Engines
The best feature of Hybrid RAG is its integration of multiple retrieval methods.
- The vector retrieval encoder converts queries and documents into high-dimensional vectors. It helps in semantic similarity search across unstructured content.
- On the other hand, a knowledge graph retrieval or structured search engine allows precise retrieval from structured datasets.
Retrieval Orchestration Layer
You can say this orchestration layer is the system’s brain. It determines how and when to leverage each retrieval engine. Orchestration layer merges and ranks results from different sources and makes sure the most relevant (contextually appropriate) information is selected.
Moreover, this layer also optimizes the inputs for the language model with better query reformulation, context window management, and relevance tuning.
Large Language Model (LLM) Generator
Once the most relevant data is retrieved, both the original user query and the curated context are sent to the generator component. There, the Large Language Model synthesizes this information to produce a context-aware response, which is tailored to the user’s needs. It is a crucial step that transforms raw data into actionable insights.
Hybrid RAG architecture is a complex one and all the layers work together to deliver context-rich AI outputs for enterprise needs.
How Hybrid RAG Works: Step-by-Step Workflow
While traditional systems struggle with enterprise complexity, Hybrid RAG follows a precise workflow. Let’s walk through the seven-step workflow that transforms your fragmented enterprise data into actionable insights:
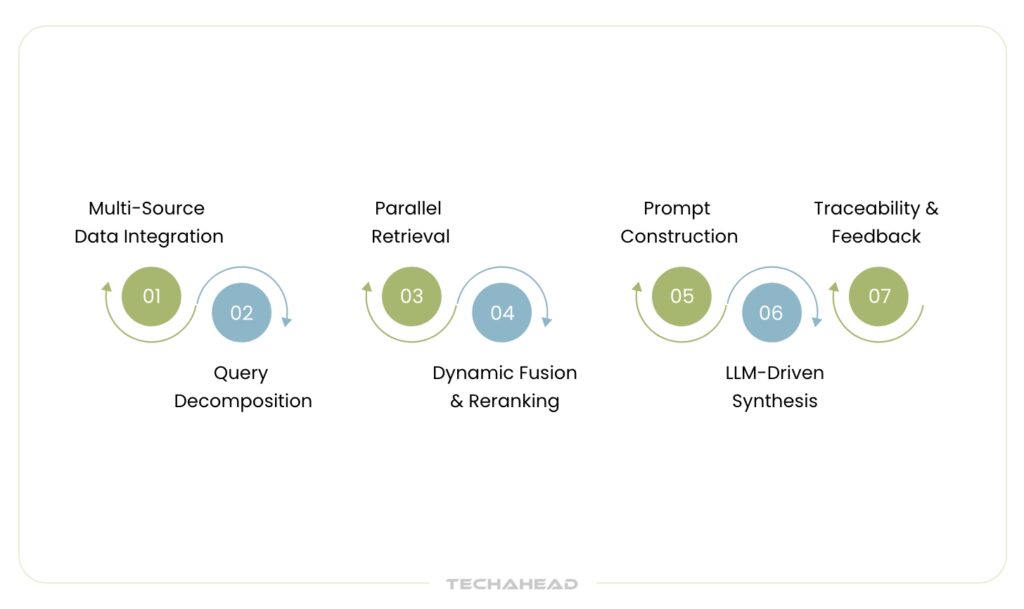
Step 1: Multi-Source Data Integration
First, the data management part, here, hybrid RAG connects different data sources, even unstructured documents, SQL databases, and knowledge graphs. Then, each data type is pre-processed; text is embedded, tables are structured, and graph data is mapped for traversal.
Step 2: Query Decomposition
Upon receiving a user query, the system decomposes it into components suitable for different retrieval engines. For example, entities and relations are extracted for graph searches, while semantic embeddings are generated for vector retrieval.
Step 3: Parallel Retrieval
Distinct retrieval engines operate in parallel:
- Vector search locates semantically similar text passages.
- Graph traversal identifies relevant nodes and relationships in knowledge graphs.
- Structured queries fetch precise facts from databases.
Step 4: Dynamic Fusion & Reranking
After that, results from all engines are dynamically fused. Advanced reranking models (powered by machine learning) prioritize results based on context relevance and query intent.
Step 5: Prompt Construction
The orchestrator balances the inclusion of structured facts and narrative context. This step makes sure the input remains within the language model’s context window.
Step 6: LLM-Driven Synthesis
Then, the language model synthesizes a response using the curated prompt and generates an output tailored to enterprise needs.
Step 7: Traceability & Feedback
As each response is linked to its source data, it helps in better traceability. For improvement, RAG uses the feedback from the users and optimizes the responses.
It is a simple step by step process, but hybrid RAG follows a more complex process to deliver context-rich, relevant answers.
Types of Data Sources in Hybrid RAG
Here is a list of structured and unstructured data sources for an enterprise-level hybrid RAG architecture:
Structured Data Sources
- Relational databases (SQL, NoSQL)
- Knowledge graphs (RDF, property graphs)
- Enterprise resource planning (ERP) systems
- Tabular datasets (CSV, Excel)
- APIs providing structured outputs
Unstructured Data Sources
- Text documents (PDFs, Word, plain text)
- Web pages and HTML content
- Emails, chat logs, and transcripts
- News articles and reports
- Multimedia content with extracted text (OCR, speech-to-text)
What are the Benefits of Using Hybrid RAG Architecture?
Understanding the core architecture is important, but what really matters is the bottom-line impact. Here is how Hybrid RAG Architecture delivers tangible business value for your enterprise:
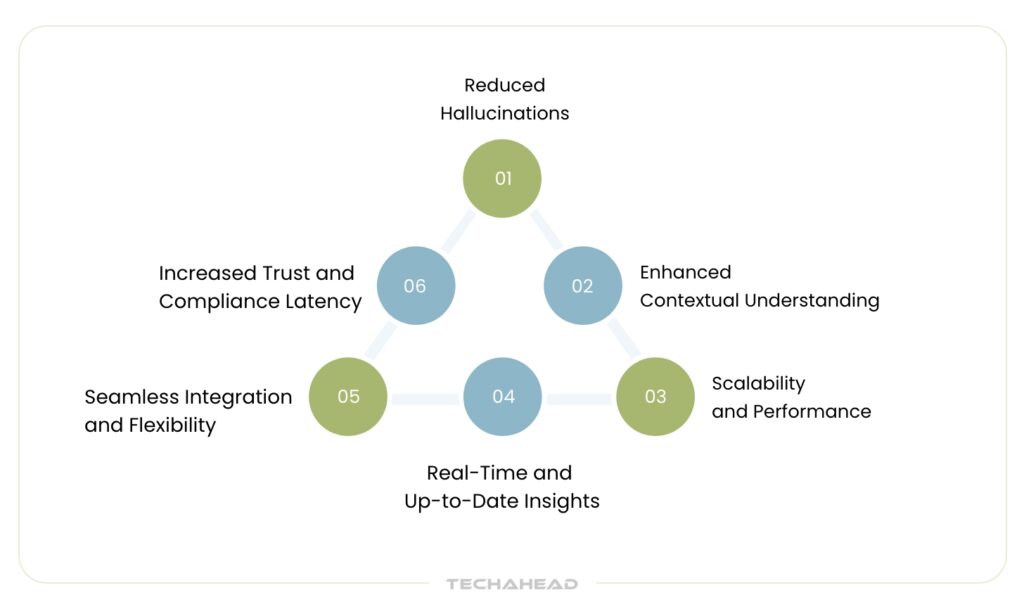
Reduced Hallucinations
Hybrid RAG Architecture offers better responses than regular Gen AI tools because it combines structured reasoning with flexible semantic search. As a result, it reduces the hallucinations even for ambiguous queries.
Enhanced Contextual Understanding
Hybrid RAG uses multiple retrieval strategies for delivering deeper contextual understanding. Knowledge graphs map relationships between entities and allow the model to interpret nuanced queries and provide richer, human-like responses. It plays an important role where interplay of data points is crucial, especially in finance, healthcare, and law.
Scalability and Performance
Hybrid RAG addresses scalability challenges through efficient design and modular retrieval mechanisms that handle large datasets. It uses dynamic orchestration, efficient indexing methods, such as
- Uses vector databases and structured indexes to quickly retrieve relevant data from massive unstructured/structured sources.
- RAG runs semantic vector search and graph or keyword retrieval in parallel.
- Adjusts retrieval strategies, optimizes resource use based on query complexity.
- Adds/removes components seamlessly, which allows the system to scale horizontally as data volume and user demand grow.
- Supports asynchronous memory updates and caching to reduce latency for enterprise applications.
Real-Time and Up-to-Date Insights
Unlike static language models (limited training data), Hybrid RAG can access and integrate the latest business information for your enterprise. It is crucial for healthcare and finance industries where regulations, market conditions, or research findings are essential.
Seamless Integration and Flexibility
Hybrid RAG is designed to work with existing enterprise infrastructure, which supports the integration of tools like SharePoint, Salesforce, wikis, legacy databases. The best part? You can unlock more value from your current information assets, which helps you make more informed business decisions.
Increased Trust
Hybrid RAG offers source-linked responses, which means better transparency and trust, which you cannot expect from regular open source Gen AI models. Here, users can verify the origin of every answer that supports informed business decisions.
Common Use Cases for Hybrid RAG in Different Industries
Hybrid Retrieval-Augmented Generation (RAG) architecture is transforming different industries from healthcare to finance. Here is how different industry leaders are leveraging the Hybrid RAG model to solve their complex business challenges:
Healthcare
In healthcare, Hybrid RAG helps medical professionals quickly synthesize clinical evidence. They use research papers, hospital protocols, and patient records as the main data sources.
IBM Watson Health, for example, uses RAG to provide doctors with tailored treatment recommendations from (structured and unstructured) electronic medical records (EMRs). As a result, it reduces review time and supports faster, evidence-based clinical decisions.
Retail and E-commerce
Retailers like Walmart deploy AI agents to manage real-time inventory data and product manuals. These systems deliver personalized, accurate responses to customer queries in the ecommerce industry, which improves satisfaction and reduces return rates. It works like RAG, which usually updates answers based on seasonal trends and customer needs that helps to optimize customer engagement.
Logistics and Supply Chain Optimization
DHL uses Hybrid RAG to optimize delivery routes by integrating real-time traffic data, logistics databases, shipment records. RAG helps them in dynamic route planning, which reduces significant operational costs. The combination of semantic search and structured data retrieval helps them adapt rapidly to changing conditions.
Financial Services
Financial firms leverage RAG to analyze market trends, financial reports, and regulatory documents. JP Morgan’s RAG-based systems reduce settlement errors and speed up legal document retrieval. RAG also helps banking and other financing institutions provide better investment decisions with up-to-date market information.
Education and Adaptive Learning
In EduTech, you can employ RAG to deliver personalized learning experiences tailored to individual student needs. It offers data charts and student-friendly responses that improve knowledge retention.
Legal Industry
Law firms utilize RAG to quickly scan vast legal databases, statutes, and case laws. Here, keywords and semantic retrieval help lawyers build stronger cases with less research time. As a result, it accelerates legal workflows and quality of advice.
Indeed, Hybrid RAG empowers enterprises across industries to unlock the full value of their diverse data assets.
What are the Challenges of Enterprise Hybrid RAG?
- Poor quality or siloed data may lead to irrelevant AI responses. As it may take a long training time for optimized performance.
- As enterprise data grows, maintaining fast retrieval and response times becomes challenging.
- Integrating Hybrid RAG with legacy infrastructure needs significant investment.
- Handling sensitive enterprise data raises concerns around data privacy, access control.
- Sometimes, Hybrid RAG systems also struggle to consistently retrieve and rank the most relevant information.
- Ongoing maintenance of data pipelines, vector indices, and system updates becomes resource-intensive.
Best Practices for Building a Hybrid RAG System
Building a successful Hybrid RAG system is not about connecting data sources; it is about architecting a foundation that scales with your business growth.
1. Modular Architecture
Design your Hybrid RAG system with a clear separation between the retriever, generator, and orchestration layers. This modularity is good for independent updates, easier debugging, and seamless scaling. Microservices or containerized deployments are recommended for flexible scaling.
2. Data Preparation and Intelligent Chunking
Effective data ingestion and chunking are essential for hybrid RAG. You can also use semantic or hierarchical chunking strategies for improved retrieval accuracy. Besides that, enrich your data with metadata such as timestamps, authors, and topics to boost both search relevance. Regularly prune outdated or duplicate content to keep your knowledge base current.
3. Embedding Model and Index Optimization
Select embedding models tailored to your domain, such as Sentence-BERT or domain-specific transformers. Moreover, you can optimize your vector database with sharding, caching, and appropriate similarity metrics for high-throughput retrieval. Fine-tune your models/retrieval strategies based on user feedback.
4. Hybrid Retrieval and Re-ranking
Developers combine vector-based semantic search with graph-based retrieval for a better outcome. You can also implement advanced re-ranking algorithms to prioritize the authoritative results.
5. Security & Compliance
Developers usually design RAG to provide source linked responses that offer transparency. Moreover, you can secure data pipelines, granular access controls, and audit trails for fetching essential outputs.
Future Trends in Hybrid RAG and Retrieval-Augmented Generation
The industry is moving towards “RAG as a Service.” It means cloud-based solutions will abstract much complexity, which allows your teams to quickly integrate Hybrid RAG into existing applications without significant infrastructure investments. Indeed, the journey with Hybrid RAG is just beginning and you need to understand the future trends to maintain a competitive edge in your industry:
Federated RAG Architectures
Federated RAG is emerging that encourages collaboration across organizations without sharing raw data. This approach supports secure knowledge sharing, especially in regulated industries like healthcare and finance.
Real-Time and Edge Deployment
Hybrid RAG systems can be deployed at the edge for real-time applications. For example, Walmart’s Edge RAG agents autonomously update shelf inventory and pricing based on live store conditions, while JP Morgan’s “RAG-on-Edge” reduces latency. It provides ultra-low-latency and context-aware responses.
Multimodal and Cross-Lingual Retrieval
Future RAG systems will integrate multimodal data, text, images, audio, and video. It expands the range of queries they can address. Cross-lingual retrieval capabilities are also advancing to expand the use of RAG in different industries.
Automated Knowledge Base Management
Automated pipelines for data ingestion, deduplication, and re-indexing are becoming standard. As a result, you can expect a fresh and relevant knowledge base. Intelligent summarization and context window management will help overcome LLM input limitations.
Is Hybrid RAG Right for Your Enterprise?
If you are seeking faster, more accurate insights from your data, then Hybrid RAG is a smart investment. You can benefit from reduced operational costs, and the ability to scale without complexity. If you want to make confident decisions, backed by AI, then hybrid RAG should be your best investment.
Leading enterprises are already seeing measurable ROI and competitive advantages. As companies are already realizing transformative gains, now is the time to future-proof your business with Hybrid RAG and unlock the full value of your data assets.
Conclusion
The future of enterprise AI is not about choosing between accuracy and innovation; it is about having both. Hybrid RAG architecture is the evolution your organization needs to unlock the full potential of your data assets.
Ready to turn your fragmented data into a competitive advantage? Do not let your competitors get ahead while you are still dealing with AI hallucinations and siloed information.
TechAhead’s expert development team has successfully implemented advanced AI solutions for Fortune 500 companies, delivered 30%+ cost reductions and measurable business outcomes. Schedule a strategic consultation today to discover how we can transform your enterprise AI infrastructure and unlock millions in operational savings.



