







Staff Augmentation
Access top-tier talent on demand: Dedicated, Hourly, or Flexible.






























 Copy Link
Copy Link Share on X
Share on X Share on Facebook
Share on Facebook Share on LinkedIn
Share on LinkedIn
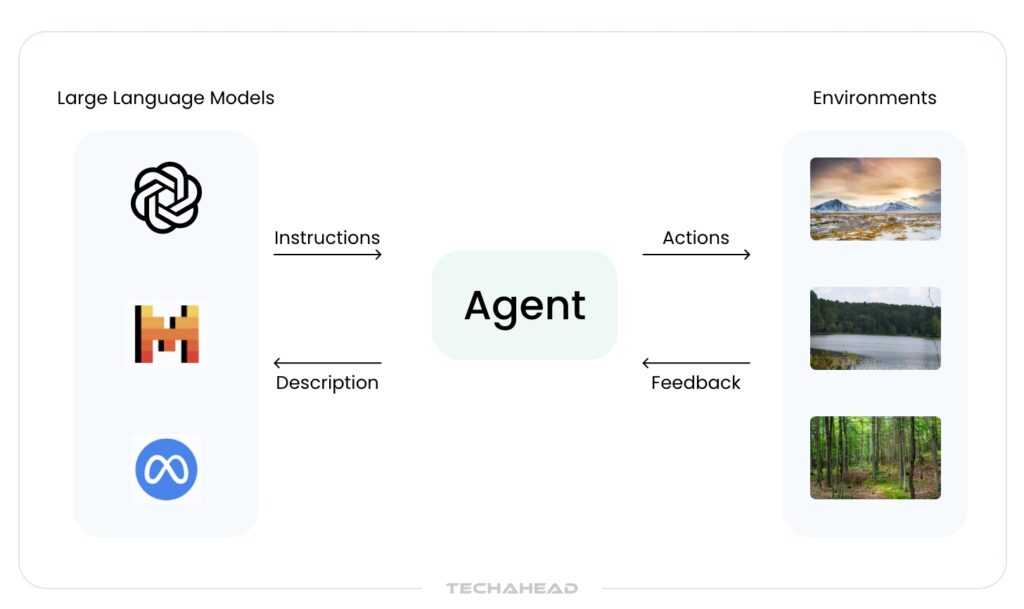
Imagine a future where artificial intelligence doesn’t just follow instructions but collaborates with you. It understands your goals, helps you plan your day, writes code, summarizes reports, or even guides you through high-stakes business decisions. This isn’t science fiction. It’s the promise of LLM-powered autonomous agents. These advanced systems are powered by large language models (LLMs) like GPT-4, and they’re designed to operate more like digital teammates than traditional tools.
At the heart of these agents are models that understand and generate human language. But what makes them truly powerful is their ability to act autonomously: they can make decisions, break down complex tasks into smaller steps, and interact with tools, APIs, or even other agents to get the job done. Whether it’s an agent scheduling your meetings, debugging code, or researching scientific topics, their flexibility and adaptability open up a new way of working with AI.
In this blog, we’ll take a closer look at how these agents are structured, what powers them under the hood, the challenges they face, the various forms they can take, and, most importantly, how they’re reshaping the way we think about intelligent systems in our personal and professional lives.
What are LLM Agents?
LLM agents are AI-powered systems that understand natural language and convert it into meaningful conversations to perform specific tasks based on the user’s input. These AI agents are powered by LLM model algorithms. It trains them on the basis of large datasets of human languages that interpret context, generate coherent responses, and simulate human-like interactions.
The LLM agent is built on deep learning frameworks that enable it to adapt, learn patterns, and respond intelligently to any input. This allows them to not only process and understand language but also to produce responses that feel natural, intuitive, and context-aware.
Moreover, these agents serve as the backbone for a variety of applications, including intelligent virtual assistants, AI-powered chatbots, content creation platforms, customer support tools, and automation systems. By integrating LLM agents into these solutions, businesses can streamline operations, enhance user experiences, and scale personalized services without relying heavily on human intervention.
LLM agents are transforming how we interact with machines, making communication smoother, smarter, and more human-like than ever before.
Core Components of LLM Agents
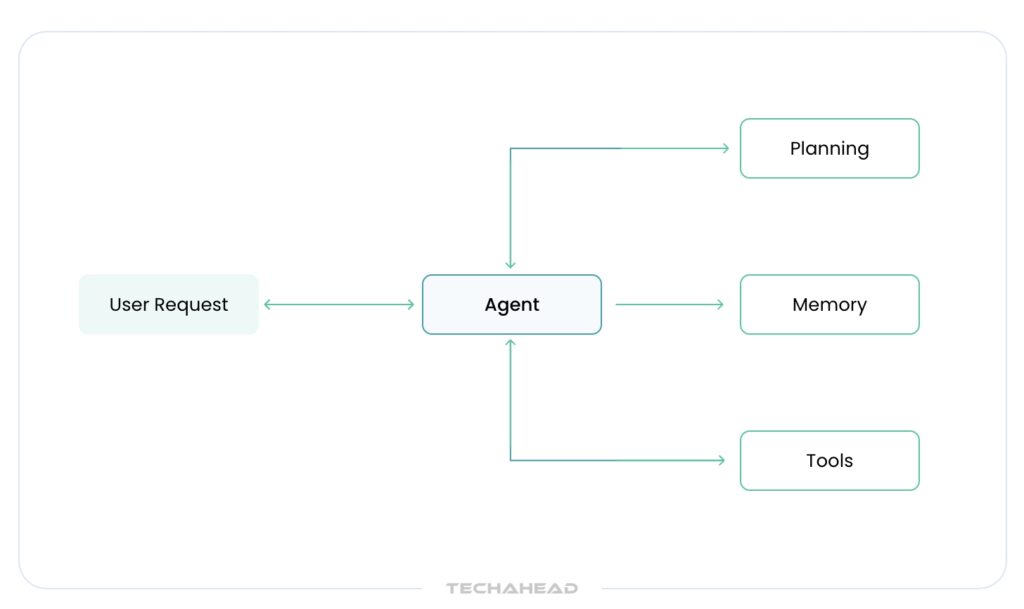
To function effectively in dynamic and multi-faceted environments, large language model agents are built using a structured framework comprising four essential components: the Agent (or brain), Planning, Memory, and Tool use.
Agent (The Cognitive Core)
At the heart of every LLM agent lies a powerful computational engine, typically a large language model or a large action model. This serves as the agent’s “brain,” responsible for understanding natural language processing, interpreting context, and generating coherent, human-like responses.
When a user interacts with the agent, the process begins with a prompt. This prompt acts as a directive, instructing the agent on the task, tone, or tools to use. It’s akin to giving strategic instructions to a digital co-pilot before takeoff, ensuring clarity of purpose from the start.
Moreover, agents can be tailored with personas, predefined roles, or characteristics that shape how they communicate or solve problems. Whether it’s a financial advisor persona for budget planning or a tech support persona for troubleshooting, personas enhance task relevance and create a more personalized experience.
These core components integrate powerful language understanding with customizable behavior, enabling the agent to adapt its tone, strategy, and interaction style to best meet user expectations.
Memory (Short-Term and Long-Term Recall)
Memory plays an important role in helping LLM agents maintain continuity, learn from past interactions, and deliver more informed responses. It is typically categorized into two types:
- Short-term memory: This functions like the agent’s scratchpad. It temporarily holds relevant information during a conversation, such as the user’s current question, context, or recent responses. Once the session concludes, this data is typically discarded. However, it plays a vital role in keeping the agent coherent and context-aware throughout ongoing interactions.
- Long-term memory: This is more like an evolving knowledge base or journal. It allows the agent to retain critical insights, patterns, and historical preferences across sessions. For instance, an AI assistant could remember a user’s preferred scheduling style or commonly asked queries, allowing for more personalized service in the future.
By combining short-term responsiveness with long-term contextual learning, LLM agents provide more relevant, efficient, and humanlike interactions, especially in complex or recurring task scenarios.
Planning (Task Decomposition and Strategy Building)
Planning is what empowers LLM agents to act methodically and solve complex problems in structured ways. It allows them to break down large objectives into smaller, actionable steps and then execute or adjust those steps as the task progresses.
There are two key subcomponents of this planning process:
Plan Formulation
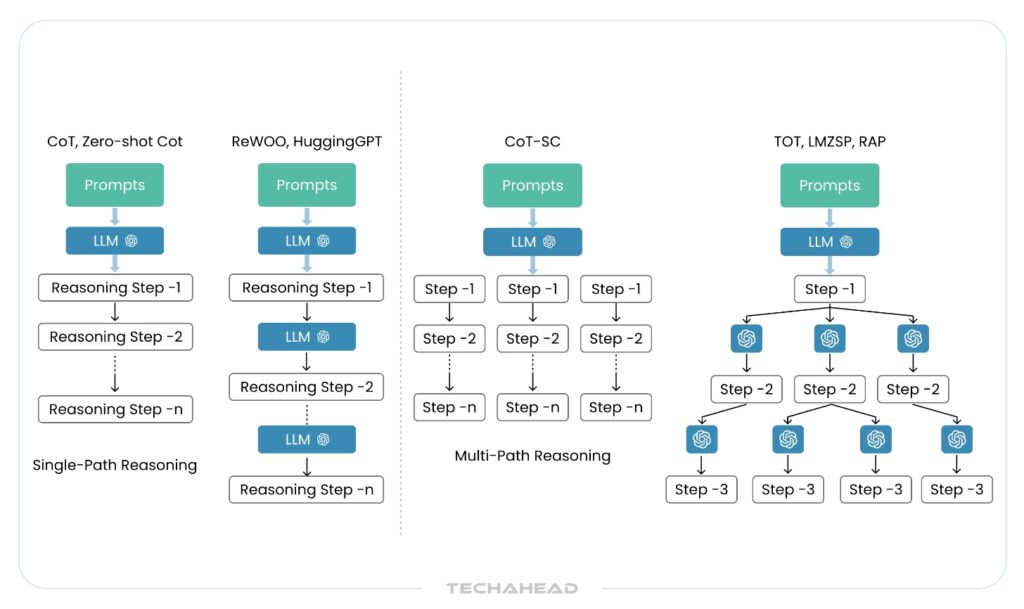
This stage is all about strategic decomposition. The agent evaluates the overall objective and identifies sub-tasks that need to be completed to achieve it. Various planning frameworks exist here:
- Linear planning: A step-by-step breakdown where tasks are executed sequentially.
- Chain of Thought (CoT): A more dynamic approach where the agent reasons through each sub-task one at a time, adapting along the way.
- Tree of Thought (ToT): An evolution of CoT, this strategy explores trees to identify the most effective one.
- Hierarchical and Multi-Path Planning: These models break down decisions into layers or explore multiple reasoning paths simultaneously, helping the agent weigh various options before choosing the best strategy.
Although LLMs are highly capable, they can face challenges with niche or domain-specific tasks. In such cases, integrating them with domain experts or specialized sub-agents helps enhance accuracy and reliability.
Plan Reflection
Once a plan is in motion, the agent must be able to reflect on its effectiveness. This involves evaluating outcomes, analyzing results, and adjusting the strategy based on feedback or new information.
Techniques like ReAct (Reason + Act) allow the agent to alternate between thinking, taking action, and observing outcomes in a feedback loop. Another method, Reflexion, uses internal dialogue and model-driven introspection to fine-tune the plan. These approaches empower agents to evolve their strategies in real-time, delivering results that align better with user expectations and environmental feedback.
Tool Use (External Interaction and Execution Capability)
To extend their capabilities beyond just text processing, LLM agents are equipped to use external tools. These tools serve as functional extensions that allow the agent to interact with real-world systems, gather data, perform calculations, and automate actions.
Some examples of how LLM agents take the tool use:
- MRKL (Modular Reasoning, Knowledge, and Language): This framework uses a suite of specialized tools and models, such as calculators, APIs, or search engines, connected through a central LLM that routes tasks to the right module. It mimics a dispatch system where the LLM assigns the job to the most qualified “expert” tool.
- Toolformer and TALM: These models are fine-tuned specifically for seamless interaction with APIs. For instance, they can plug into financial services APIs to provide market forecasts or health data APIs for wellness tracking, enabling real-time insights and decision support.
- API-Bank: This benchmark tests how well LLM agents can operate across a set of 50+ APIs for everyday tasks, like booking appointments, managing smart homes, or accessing healthcare records, making it a litmus test for real-world tool integration.
Tool usage represents the action arm of LLM agents that bridges the gap between language understanding and real-world execution. It turns those executions from conversational models into intelligent digital operators.
Types of LLM Agents and Their Use Cases
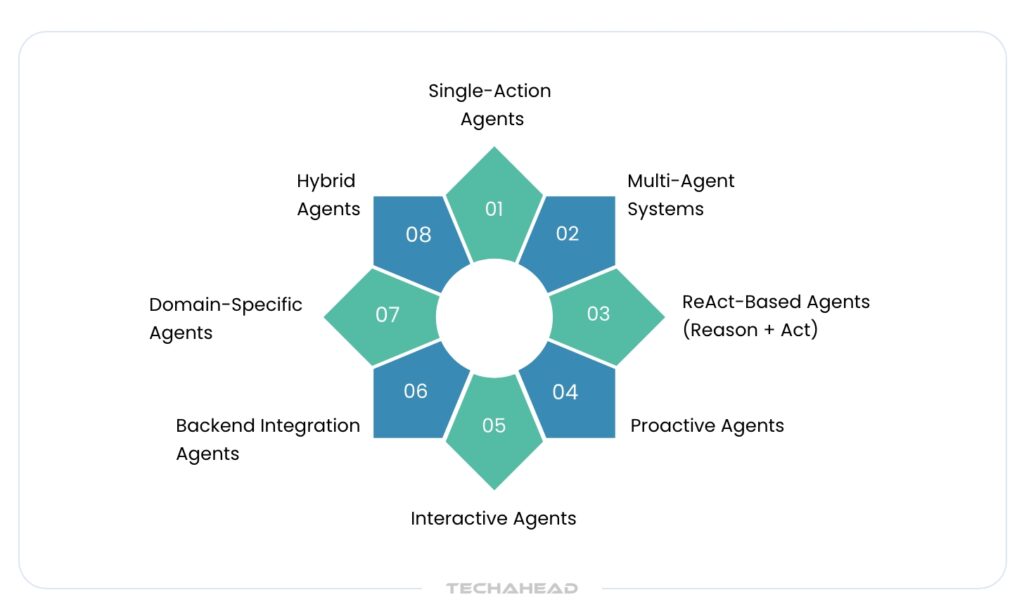
LLM agents come in a variety of types, each tailored to different operational needs and user experiences. Selecting the right type depends on your use case, whether you need an agent for simple automation, complex decision-making, real-time interaction, or domain-specific intelligence. Below is an expanded guide to the most common categories of LLM agents:
Single-Action Agents
These are purpose-built agents designed to execute one action or complete a specific task with high precision. Think of them as focused tools, like a laser beam aimed at a narrow objective.
- Task-oriented Agents: These agents are trained to complete specific tasks such as answering a customer support ticket, booking an appointment, or handling e-commerce queries. They work best when the problem scope is clearly defined and doesn’t require deep reasoning or multi-step interaction.
- Conversational Agents: Primarily designed for natural language engagement. These agents mimic human conversation. They’re commonly used in customer service chatbots, help desks, or virtual assistants, aiming to create fluid and intuitive interactions with users.
Multi-Agent Systems
In a scenario where solving a problem requires coordination, LLMs can be deployed as collaborative units, each specializing in a sub-task.
- Collaborative Agents: These agents work together, often in a divide and conquer model, to tackle complex tasks like software development, research, or strategic decision-making. One agent might gather data, while another interprets it, and a third makes recommendations, each acting as a specialist in a digital team.
- Competitive Agents: Modeled after game theory principles, these agents operate in adversarial settings. For example, one agent may act as an attacker and another as a defender in cybersecurity training. They’re often used in reinforcement learning scenarios to simulate market conditions or stress-test systems.
You can also learn more about Multi-Agent systems here.
ReAct-Based Agents (Reason + Act)
These are event-driven agents that operate by observing the environment, reasoning about it, and taking appropriate action.
- Reactive Agents: These agents are triggered by real-time events like a stock market fluctuation, sensor reading, or social media trend. They analyze the input and respond instantly, making them ideal for use cases like fraud detection or live monitoring.
- Rule-Based Agents: Operate based on predefined conditions or “if-this-then-that” logic. While less flexible, they are highly dependable for scenarios like compliance monitoring, alert generation, or system diagnostics.
Proactive Agents
Unlike reactive agents, proactive agents are predictive. They act before a problem occurs or a request is made. This action is made on the day-to-day activities done by the user.
- Predictive Agents: These use historical data and patterns to anticipate user needs. For instance, they might recommend restocking inventory before levels run low or suggest a meeting time based on past scheduling habits.
- Preventive Agents: These go a step further by identifying potential risks and taking action to avoid them. In IT operations, for example, they can analyze logs to predict system failure and apply fixes ahead of time.
Interactive Agents
These agents prioritize dynamic, two-way communication and user engagement.
- Question-Answering Agents: They respond to user queries using structured or unstructured data sources. Examples include academic tutors, search assistants, or customer-facing bots integrated with a knowledge base.
- Advisory Agents: These go beyond simple answers. By analyzing user behavior, preferences, and historical choices, they provide tailored recommendations. Think of them as personal consultants—ideal for domains like finance, health, or education.
Backend Integration Agents
These agents serve as connectors between LLMs and external systems, enabling direct interaction with databases and APIs.
- SQL Agents: Designed to interact with databases, these agents can write, execute, and interpret SQL queries. They’re useful in business intelligence tasks, like retrieving customer data, generating reports, or tracking KPIs.
- API Agents: These interact with third-party applications via APIs. For instance, an API agent can fetch live weather data, submit a form on a web app, or trigger a smart home device. They are vital for automation workflows and digital integrations.
Domain-Specific Agents
These are highly context-aware agents, customized for specific industries or verticals.
- Self-learning Agents: Supporting reinforcement learning and feedback loops, these agents continuously improve their performance. They learn from each task and get better with each iteration.
- Self-Repairing Agents: These are built with diagnostic capabilities, allowing them to detect their own failures and apply fixes. For example, if an agent encounters a logic error, it can debug and correct its code autonomously.
Hybrid Agents
Combining the strengths of multiple agent types, hybrid agents are versatile and adaptable in dynamic environments.
- Multi-Functional Agents: These agents blend skills, such as a chatbot that can also analyze financial data, submit forms, and send alerts. They are suited for complex customer journeys that require seamless transitions between multiple tasks.
- Context-Aware Agents: These agents adjust their behavior based on situational context, like user location, time of day, or emotional tone. This adaptability makes interactions feel more natural and relevant, enhancing user satisfaction.
Choosing the right type of LLM agent depends on your goals, whether you need speed, specialization, adaptability, or autonomy. As the field evolves, we are moving toward a future where hybrid, context-aware, and self-improving agents will become the norm, driving intelligent automation across industries.
Architecture and Design Principles for LLM Agents
Designing an advanced platform that supports large language models and intelligent AI agents requires a forward-thinking architecture. This architecture must not only be adaptable but also capable of scaling with growing demands, evolving technologies, and diverse integration needs. To ensure long-term success, the following core design principles should guide the development process.
Scalability
As the number of users, agents, and deployed models increases, the platform must be able to scale seamlessly. This means the underlying infrastructure should support horizontal scaling, adding more servers or instances. As well as vertical scaling by upgrading resources like memory and processing power.
Scalability ensures consistent performance under high loads, which is essential for enterprise-grade deployments and real-time AI applications.
Flexibility
The architecture should be flexible enough to support different types of LLMs, from proprietary models to open-source variants. It should also allow integration with a variety of data sources, whether structured databases, unstructured documents, APIs, or real-time data streams.
This flexibility empowers developers to experiment, customize, and deploy AI agents tailored to specific business needs without overhauling the core system.
Modularity
Using a modular design approach enables the platform to evolve without causing disruptions. Each component, such as model training modules, data connectors, orchestration layers, or user interfaces, should be independently replaceable or upgradable.
For example, if a newer LLM becomes available, it should be easy to integrate it without reengineering the entire system. This also accelerates development cycles and simplifies maintenance.
Reliability and Fault Tolerance
In production environments, system reliability is non-negotiable. The platform must be engineered with strong fault tolerance capabilities, including error-handling routines, failover strategies, and real-time health monitoring.
These mechanisms help maintain uptime and service continuity, even when individual components fail. By minimizing system crashes and ensuring quick recovery, the platform can support mission-critical operations with confidence.
Security and Privacy
Protecting user data and ensuring platform security should be a top priority. This includes implementing end-to-end encryption, access control policies, secure authentication mechanisms, and compliance with data protection regulations like GDPR or HIPAA. Additionally, AI agents should be built with privacy-aware processing capabilities, ensuring sensitive information is handled ethically and securely across all workflows.
Observability and Monitoring
To ensure operational excellence, the platform must include robust observability features. This involves real-time monitoring dashboards, detailed logging systems, alerting mechanisms, and performance analytics. These tools enable engineers to quickly identify bottlenecks, debug issues, track usage patterns, and optimize system performance over time. Effective observability leads to proactive maintenance and data-driven decision-making.
Extensibility
Given the fast-paced evolution of AI technologies, the architecture must be extensible by design. This means it should support plug-and-play compatibility with emerging tools, frameworks, and model architectures. Whether it’s incorporating new AI paradigms like multi-modal models or integrating third-party services, the system should be built to grow and adapt with future innovations without major rework.
Challenges in Implementing LLM Agents

While Large Language Model (LLM) agents have revolutionized human-computer interaction by enabling intelligent, autonomous decision-making, their practical deployment still comes with notable limitations. To harness their full potential, it’s essential to recognize and address these critical pain points.
Context Window Limitations
One of the most prominent limitations is the restricted context window. The amount of information an LLM can process and retain during a session. This means that during long conversations or multi-step tasks, agents may “forget” earlier inputs or lose sight of crucial details. For example, an agent assisting in project management might forget initial client requirements halfway through task planning.
While solutions like vector databases and external memory augmentation offer partial workarounds by enabling retrieval of relevant information on demand, they aren’t foolproof. These methods still rely on proper indexing, prompt framing, and semantic accuracy, which can break down in complex or noisy contexts.
Challenges in Long-Term Planning
LLM agents often struggle with strategic foresight, especially when a task requires sustained effort over time or needs adaptive responses to unexpected hurdles. Unlike humans, who can intuitively modify their plans based on evolving circumstances, LLM agents tend to operate within a fixed, prompt-driven scope. Their reasoning is generally reactive rather than proactive, which limits their effectiveness in domains like supply chain planning, software development, or research projects that require iteration and resilience.
Frameworks like Tree of Thought (ToT) and hierarchical planning agents aim to bridge this gap, but achieving robust, human-like planning over extended timelines remains an open research problem.
Inconsistent and Unreliable Outputs
Since LLM agents primarily communicate and act using natural language, they are prone to inconsistencies in output formatting and execution fidelity. For instance, when querying a database, even a minor deviation in syntax or structure can cause errors or misinterpretation of results. These inconsistencies often emerge when the model attempts complex tool use, coding tasks, or multi-turn workflows.
To improve reliability, developers often integrate intermediate validation layers or apply structured prompting, but these add to system complexity and don’t fully eliminate the risk of misexecution.
Difficulty Adapting to Specialized Roles
Another challenge is role alignment. LLM agents need to dynamically assume different roles depending on the use case, such as acting as a lawyer, a financial advisor, or a virtual assistant. However, fine-tuning agents for niche domains or infusing them with human-aligned values, like ethical reasoning or cultural nuance, is both technically and philosophically complex.
While techniques such as instruction tuning and reinforcement learning with human feedback (RLHF) offer some improvements, they are costly and still lack precision when applied across a broad spectrum of professional or value-sensitive contexts.
High Dependence on Prompt Engineering
Prompt engineering is the command center for any LLM agent, but it’s also a major bottleneck. A well-crafted prompt can yield brilliant results, while a slightly vague or poorly structured one can cause total failure. This extreme sensitivity to input phrasing means that much of an agent’s performance hinges on trial-and-error prompt refinement, which is both time-consuming and prone to human bias.
Emerging approaches like self-prompting, auto-prompt generators, and multi-shot learning help reduce this burden, but the need for precision still makes scalable deployment a challenge.
Knowledge Management and Misinformation Risks
Keeping an LLM agent’s knowledge current, relevant, and unbiased is another major hurdle. These agents are typically trained on massive datasets, which may contain outdated facts, inaccuracies, or cultural biases. Without careful curation and dynamic knowledge updates, agents can inadvertently produce hallucinations, confidently delivering incorrect or misleading information.
Techniques like retrieval-augmented generation (RAG) and domain-constrained training improve factual grounding, but real-time validation and filtering remain necessary for high-stakes applications like healthcare, legal analysis, or finance.
Resource Intensity and Efficiency Trade-offs
Operating an LLM agent at scale requires significant computational resources. From large model inference to memory storage and real-time API calls, the cost of running these systems can be substantial, especially when serving multiple users simultaneously or processing large datasets.
This makes latency optimization, model distillation, and efficient caching critical for enterprise adoption. Balancing performance, scalability, and cost is an ongoing challenge that directly impacts the feasibility of deploying LLM agents across industries.
Key Benefits of LLM Agents
The architecture of LLM agents offers significant advantages across a wide range of applications. These agents are not only capable of handling intricate tasks, but they also exhibit a high level of adaptability, continuous improvement, and collaborative potential. Below are some of the core benefits they bring to the table.
Advanced Problem Solving
LLM agents excel at breaking down and tackling complex challenges. Whether you’re managing a large-scale project, developing software, or processing large volumes of data, these agents can take on multiple roles to streamline the workflow.
For example, they can autonomously generate detailed project roadmaps, identify logical steps, assign priorities, and even write functional code when necessary.
Once the task is complete, they can synthesize vast information into concise, human-readable summaries, saving time and boosting clarity in decision-making.
Self-Evaluation and Output Verification
Unlike traditional systems that rely entirely on external validation, LLM agents are increasingly self-aware and self-checking in their operations.
- They can initiate unit tests to validate the integrity and functionality of the code they produce. This minimizes bugs and reduces the need for manual QA.
- Additionally, agents can query online sources or access internal databases to verify the accuracy of information before presenting it.
- This built-in validation process ensures greater trust in the outputs, especially for critical applications like legal research, medical suggestions, or financial analysis.
Continuous Performance Improvement
LLM agents are designed with iterative learning mechanisms, allowing them to refine their behavior and outputs over time. They can identify errors in real-time and make corrective adjustments without halting the task flow. This ability to adapt dynamically improves overall system resilience.
Moreover, in collaborative environments, multiple agents can peer-review each other’s outputs, offering critiques, alternative perspectives, or optimized solutions. This team-based reasoning drives higher-quality results and innovation.
Over time, this feedback loop fosters smarter, more consistent performance, making LLM agents increasingly reliable as they gain experience.
Conclusion
LLM agents are becoming essential in solving tasks that go beyond simple question-and-answer formats. They can think ahead, search for the right information, remember past conversations, and even learn from experience to improve over time. This makes them valuable in situations where the path to the answer isn’t always straightforward.
Still, they’re not without limitations, they can forget important context quickly and often require very clear instructions to work effectively. But as we continue to refine their design and address these challenges, these agents will grow even smarter, more reliable, and better equipped to handle the complex demands of real-world problems.

FAQs
What’s the difference between a large language model (LLM) and an AI agent?
LLMs are designed to understand and generate human-like text based on the input they receive. In contrast, AI agents go a step further. They use LLMs as their core but are capable of making decisions, breaking down tasks into smaller parts, and completing those tasks on their own. Essentially, LLMs provide the language capabilities, while AI agents use those capabilities to act independently and accomplish goals.
How do large language models work?
At the heart of LLMs is how they represent words and their relationships. Traditional models treated each word as a fixed number, which made it hard to understand context or similarity. LLMs overcame this by using word embeddings, multi-dimensional vectors that position words in a space where similar meanings are close together. This allows the model to better understand the context and relationships between words when generating or interpreting text.
What is a general-purpose LLM?
General-purpose LLMs are built to handle a wide variety of tasks, from answering questions to drafting emails or summarizing articles. They’re flexible but may not offer deep expertise in niche areas. In contrast, domain-specific LLMs are trained for particular use cases, like medical or legal content and deliver more accurate and relevant responses within that field, though they may not perform well outside of it.
What is function calling in LLMs?
Function calling allows an LLM to figure out which function to use from a list of options based on a user’s request and then provide the correct inputs for that function. Instead of responding with plain text, the LLM returns structured data, often in JSON format. So the system can carry out an actual task, such as fetching real-time data or performing calculations.
How do LLM functions differ from agents?
When using functions, an LLM suggests what action to take and provides the necessary inputs, but it’s up to the application to carry it out. AI agents, on the other hand, take a more active role; they can use tools directly (like APIs or web searches) and complete the actions themselves. So, while functions rely on a handoff, agents handle the execution autonomously.


