







Staff Augmentation
Access top-tier talent on demand: Dedicated, Hourly, or Flexible.






























 Copy Link
Copy Link Share on X
Share on X Share on Facebook
Share on Facebook Share on LinkedIn
Share on LinkedIn
Can you really trust your Agentic AI to make the right decisions when it matters the most?
The role of Artificial Intelligence in the current industry is very important for business operations. And this question has become more important than ever.
Enterprises are no longer just automating simple tasks; in 2025, they are heavily relying on autonomous intelligent agents to make faster decisions, interact with users, and manage complex workflows. But with these growing responsibilities comes a critical need, and that is, how do we make sure these AI agents are actually performing the way we expect them to?
Unlike traditional automation tools that follow fixed rules, modern agents, powered by Large Action Models (LAMs) and next-gen LLMs, are capable of autonomous planning, learning, reflecting on past actions, and executing multi-step tasks. They might be used in IT operations, customer service, supply chain management, or decision support systems, and they need to perform reliably under a wide range of real-world conditions.
Since these agents operate across dynamic layers, planning actions, adapting to real-time data, and utilizing external APIs, evaluation is far more complex than just checking if they gave the right answer. It requires a comprehensive evaluation framework that covers everything from task accuracy and response speed to ethical behavior and real-time adaptability.
By 2025, structured evaluation will have become a core part of agent development. Businesses are actively benchmarking their AI agents, comparing their performance across specific domains, and often finding that domain-specialized agents outperform general-purpose models like GPT-4o or Claude in enterprise settings. Recent industry reports indicate that 65% of enterprises deploy agentic workflows in production, making robust benchmarking essential.
This blog will give the evaluation framework you must know about. Keep reading, and you will understand more about the Agentic AI evaluation structure and its importance.
Key Takeaways
- Agentic AI evaluation in 2025 assesses how independently AI agents perform multi-step tasks, make decisions, and interact, ensuring they operate as intended without constant oversight.
- The CLASSic framework (Cost, Latency, Accuracy, Security, Stability) provides a structured approach to measure the real-world readiness of enterprise AI agents, moving beyond simple pass/fail metrics.
- Evaluating agentic AI is important for ensuring reliable and fair behavior in real-life scenarios, meeting strict 2025 compliance standards, building user trust, and keeping the agent adaptable to drifting data patterns.
- The agentic AI evaluation includes eight steps, where you can achieve the best evaluation of your agents as possible using techniques like “LLM-as-a-Judge.”
- Robust evaluation frameworks are necessary due to the dynamic nature of agentic AI, incorporating methods like synthetic data generation, detailed logging, automated testing, human feedback, and real-time safety controls.
What is AI Agent Evaluation?
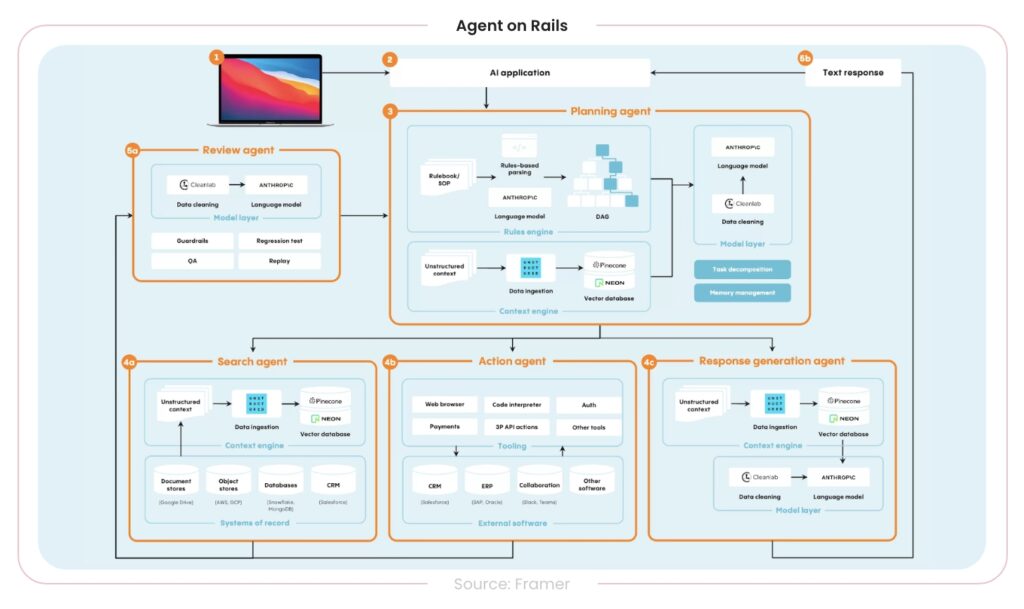
With a proper Agentic AI evaluation, it will ensure that all the agents are following their programmed goals, performing efficiently, and aligning with ethical AI standards. It is a way to make sure that the agent is reliable, smart, and safe for use within a business.
To bring structure to this evaluation process, we introduce the CLASSic framework, a practical approach widely adopted in 2025 to measure the real-world readiness of enterprise AI agents. CLASSic stands for Cost, Latency, Accuracy, Security, and Stability. Let’s break each of these down:
Cost
This refers to how resource-intensive the AI agent is. Does it require expensive cloud computing power? Is it consuming too much energy or time from your development team? In enterprise settings, it’s essential to know whether the value it delivers justifies the expense. Evaluating cost helps businesses manage their budget while scaling AI solutions effectively using optimized Small Language Models (SLMs) where possible.
Latency
Latency is the time it takes for an AI agent to respond or take action after receiving input. For customer-facing applications or real-time trading bots, speed matters. If an agent takes too long to respond due to complex reasoning chains, it could frustrate users or delay critical business decisions. So, minimizing latency is key to creating smooth and responsive AI experiences.
Accuracy
This measures how correctly the agent performs its tasks. Whether it’s answering questions, analyzing data via a Data Analytics Company, or executing API calls, the agent must deliver results that are trustworthy and precise. High accuracy is essential to build user trust and prevent “hallucinations” that can disrupt business outcomes.
Security
AI agents often handle sensitive information, from customer data to internal operations. Security evaluation ensures that the agent protects this information, follows data privacy regulations (like the updated EU AI Act), and resists adversarial attacks such as “prompt injection.” In enterprise environments, security isn’t optional.
Stability
Stability refers to how consistently the AI agent performs over time and across different scenarios. Does it maintain context over long conversations? Can it handle high workloads without suffering from model drift? A stable agent can be relied upon to operate smoothly, even during unpredictable conditions or sudden spikes in activity.
Why is it Important to Evaluate Agentic AI?

Agentic AI evaluation is a necessary task because you must know how all your AI models are interacting with your live systems. Real-world environments are unpredictable, messy, and non-deterministic, requiring rigorous evaluation for better workflow stability.
Whether it’s answering customer questions, executing trades, sorting job applications, or providing financial advice, the agent must be ready to operate fairly, responsibly, and intelligently across all kinds of scenarios.
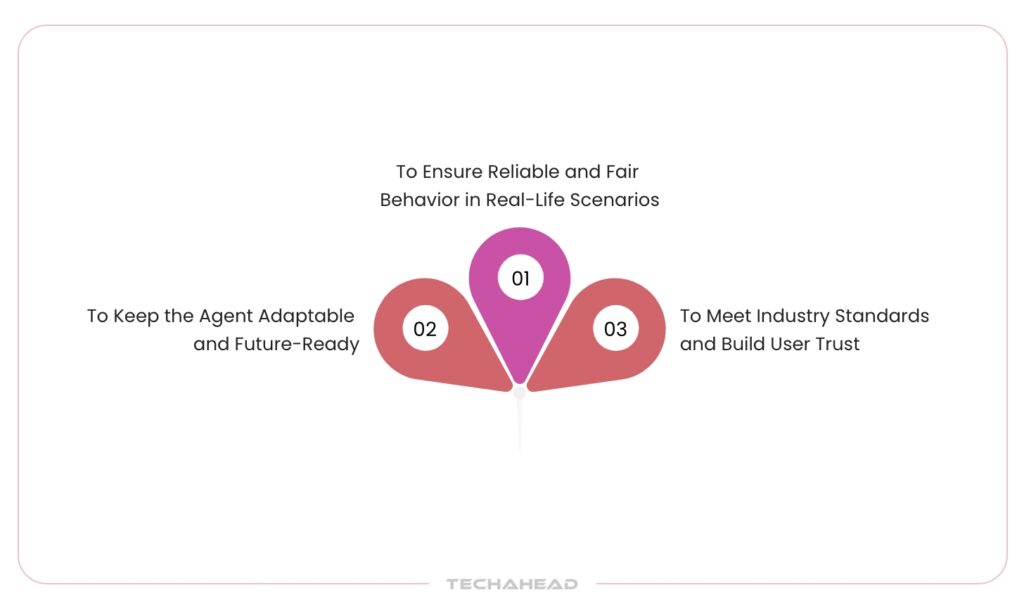
To Ensure Reliable and Fair Behavior in Real-Life Scenarios
AI agents are expected to perform consistently in both routine and unexpected situations. Just like large language models (LLMs) and generative models are tested for text quality, Agentic AI must be evaluated for action execution and potential side effects.
Take this example: if the agent is used to assess loan applications, it must treat every applicant fairly, regardless of gender, ethnicity, or income background. No bias should sneak into its decisions. Algorithmic bias must be actively detected to prevent discrimination. Similarly, if the agent functions as a virtual assistant, it should be able to answer random, quirky questions with the same confidence it shows while responding to critical API requests.
Why it matters:
Thorough evaluation helps uncover blind spots, errors, or biased behavior before the agent is released into the wild. This prevents harm, improves reliability, and ensures the agent acts ethically and accurately under pressure.
To Meet Industry Standards and Build User Trust
In sensitive fields like finance industry, healthcare, or law, AI systems operate under strict regulatory oversight. In 2025, compliance with standards like ISO 42001 (AI Management Systems) and the EU AI Act is mandatory. There are rules around data security, decision transparency, fairness, and user safety. For any Enterprise App Development Company, evaluation plays a critical role in proving that the agent meets these legal, ethical, and governance benchmarks.
By rigorously testing the AI agent against real-world tasks, compliance frameworks, and safety requirements, organizations can show regulators, clients, and users that the system has been responsibly developed and thoroughly validated.
Why it matters:
Trust is earned. When users see that an AI agent has been stress-tested, audited, and proven reliable, they’re far more likely to trust it with critical decisions—like diagnosing a patient or approving a loan. For businesses, this translates into reduced risk and increased adoption.

To Keep the Agent Adaptable and Future-Ready
Even a high-performing AI agent can become outdated if it isn’t regularly re-evaluated. As business needs change, user behavior shifts, or external APIs are deprecated, agents need to evolve too. That’s where ongoing evaluation becomes essential.
Routine testing helps detect performance degradation, identify blind spots in newer scenarios, and uncover emerging biases that weren’t visible during initial training. With each iteration, you can make targeted improvements, whether it’s optimizing function calling definitions, upgrading memory handling, or adding new compliance checks
Why it matters:
AI agents aren’t static; they live in dynamic ecosystems where tools and data sources change. Without continuous monitoring and updates, even the best-designed systems can fail to keep up. Evaluation ensures your agent stays resilient, scalable, and aligned with changing user expectations.
How Does Agentic AI Evaluation Work?
Evaluating an agentic AI requires verifying if it is performing effectively, making smart decisions, and fitting smoothly into real-world operations without causing unintended side effects. To do this properly, a structured approach is important, ideally within a broader AI observability framework that monitors the agent’s behavior and tool usage from start to finish.
Here’s a breakdown of how this evaluation process typically unfolds:
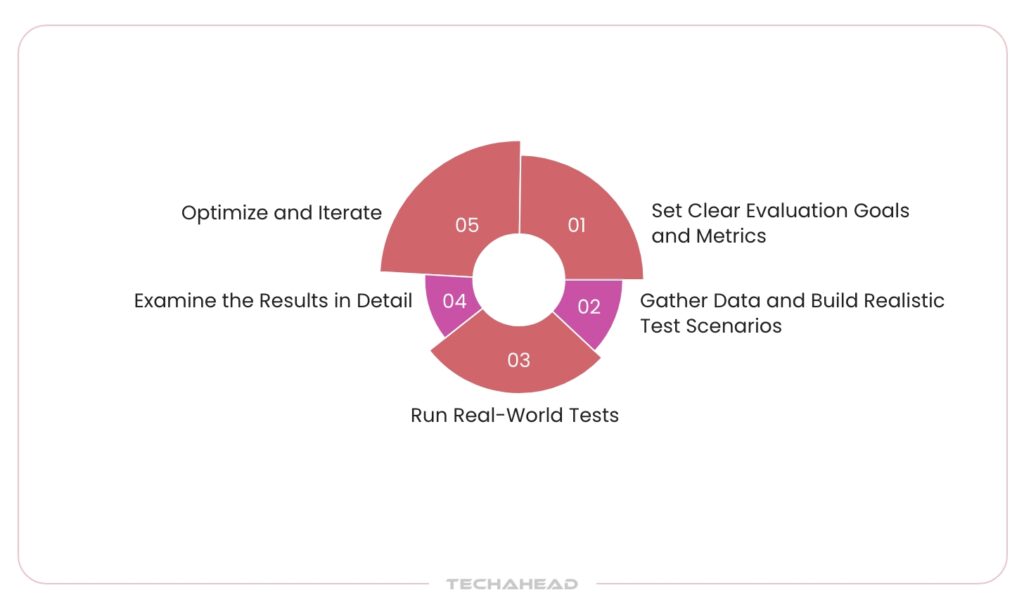
Set Clear Evaluation Goals and Metrics
Before you test anything, you must define why and what you are evaluating. Once all your questions are answered, you can choose the right evaluation metrics suited for 2025 standards. These often fall into categories such as:
- Success Rate (SR) (how accurately the agent completes the full workflow)
- Interaction and user experience (how smooth or helpful it feels to users)
- Ethical and responsible AI (does it behave fairly and transparently?)
- System efficiency (Token usage, inference latency, and API costs)
- Task-specific outcomes (is it solving the specific problem it was built for?)
This step sets the foundation for meaningful evaluation, ensuring you’re measuring what truly matters to your use case.
Gather Data and Build Realistic Test Scenarios
Your goals are set, now it’s time to test. A real-life example for using representative datasets is the edge cases that the agent might actually encounter in the field. In 2025, it is standard practice to include synthetic data generated by frontier models, where correct answers are labeled, so the agent’s responses can be compared against this “ground truth.”
At this stage, map out the agent’s entire workflow. Think about every single action the agent takes, from calling an API, passing data to another agent, to making a final decision.
Breaking down each step allows you to test and measure how well the agent handles complex tasks. Also, look at the execution path, or how the agentic AI moves through a series of steps to solve a problem. This reveals how logically and effectively it operates in real-time conditions.
Run Real-World Tests
Once the setup is ready, it’s time to put the agentic AI to the test. Run it in safe, sandboxed environments that mimic production without the risk. Simulate different user queries, mock API failures, and track how it responds. Monitor every part of the agent’s process.
By analyzing each action in isolation, you can pinpoint where the agent shines and where it struggles. Testing in diverse conditions helps ensure the agent is robust and adaptable.
Examine the Results in Detail
After testing, it’s time to dive into the data and compare the agent’s performance against the predefined success benchmarks. But evaluation isn’t just about scoring. It’s about understanding why the agent made certain decisions and whether they were appropriate.
Modern evaluation techniques also include LLM-as-a-judge, where a large language model (LLM) evaluates the agent’s actions using built-in rules and smart scoring algorithms. This allows for faster, scalable evaluation without relying solely on manual reviews.
Optimize and Iterate
The final and arguably most important step is to optimize based on what you learned. Use the insight to fine-tune how your agentic AI works.
This could involve:
- Automated Prompt Optimization (APO) for more precise responses
- Refining the underlying function calling definitions
- Improving workflow logic
- Modifying how multiple agents interact in multi-step scenarios.
For example, in customer service bots, refining the logic can reduce the time it takes to resolve issues, leading to better user satisfaction. In enterprise systems, optimizing for resource usage can improve scalability and reduce operational costs.
TL;DR for Agentic AI Evaluation Framework
| Evaluation Component | In Simple Terms |
| Synthetic Data | Creating “fake” difficult scenarios and distinct personalities to see if the agent gets tricked or confused. |
| Deep Logging | Like a “black box” flight recorder for your AI, tracing every internal thought and API call. |
| Automated Judges | Using a smarter, stronger AI (like a teacher) to grade your agent’s homework automatically. |
| Full System Testing | Testing the engine, the wheels, and the brakes separately, then driving the car to see if it actually runs. |
| Human Feedback | Having real people check if the agent is actually being helpful and polite, not just “technically correct.” |
| Safe Experiments | Using “Shadow Mode” to test new versions silently in the background before they go live. |
| Smart Upgrades | Using Fine-tuning and Prompt Engineering to teach the agent new tricks cheaply and quickly. |
| Live Guardrails | An “emergency brake” that immediately stops the agent if it tries to leak secrets or break rules. |
Why Does Agentic AI Evaluation Need a Robust Framework?

Traditional evaluation often falls short when it comes to testing current advanced agentic AI evaluation. Static benchmarks like MMLU or GSM8K don’t reflect how these agents operate in real-world, dynamic situations where state changes constantly.
To truly understand and improve agentic AI, we need a framework that is broader, deeper, and more practical.
Synthetic Data Generation for Agent Behavior Testing
Real-world data often doesn’t show the whole picture. Users usually behave in predictable ways, which means we miss out on testing edge cases, like when a user has contradictory goals or when APIs fail mid-task. That’s where synthetic data and adversarial simulation become essential.
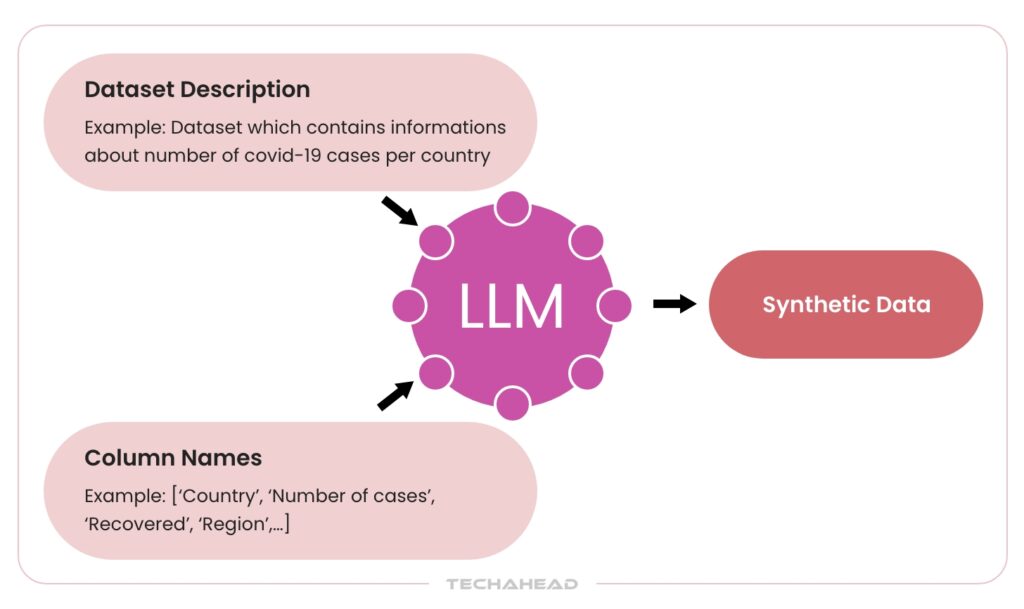
- Broader Coverage: Synthetic datasets are artificially created but modeled on realistic situations. They let you simulate tricky or rare cases that aren’t often seen in real logs.
- Stress Testing for Weak Spots: You can challenge your agentic AI with tricky prompts, like those trying to manipulate it (e.g., prompt injection or jailbreaking). This helps you find and fix vulnerabilities.
- Dialogue Simulation: Synthetic data can also mimic long conversations with varied tones, partial memory retrieval, or even shifting user needs. This makes testing more reflective of real-life user interaction.
Detailed Logging and Workflow Analysis
Agentic AI often breaks tasks into several internal steps, like retrieving memory, planning a response, or calling external tools. Capturing and analyzing every step is vital using modern observability tools.
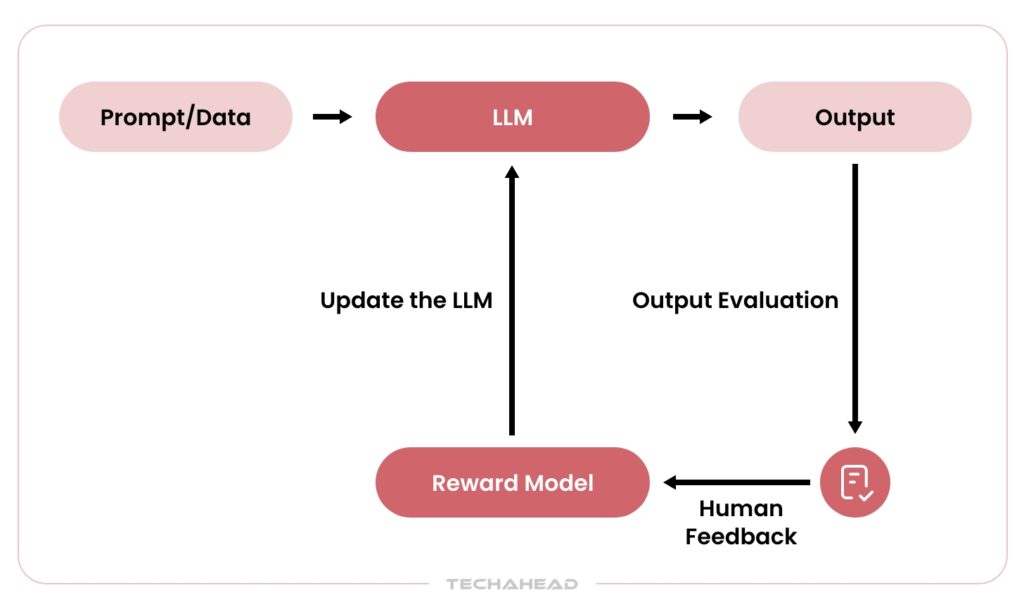
- Finding Root Causes: If something goes wrong, distributed traces help track the issue. Was the misunderstanding due to a vague prompt, a hallucinated memory, or a broken API call?
- Tuning Performance: By looking at the trace logs, you can spot repetitive actions, slow processes, or inefficiencies, and then fix them.
- Uncovering Bias: Logs also reveal patterns in decision-making. This helps identify hidden biases, especially in workflows like recommendations or planning.
Scalable and Automated Testing
Manually testing every feature or output isn’t practical. Especially when agentic AI is expected to run continuously and adapt over time. You need automation within your CI/CD pipeline to stay ahead.
- Agent-as-Judge: A separate superior model (like GPT-5 or Claude 3.5 Opus) evaluates your main agent by scoring each decision it makes, not just the final outcome.
- Smarter Metrics: Instead of simple pass/fail grades, use detailed metrics like:
- Tool Utilization Efficacy (TUE): How well the agentic AI uses external tools.
- Memory Coherence and Retrieval (MCR): How accurately it pulls relevant past data.
- Continuous Testing: These automated checks should run every time a change is made to the code, logic, or prompt format. That way, you catch problems early.
Evaluating Individual Modules and the Whole System
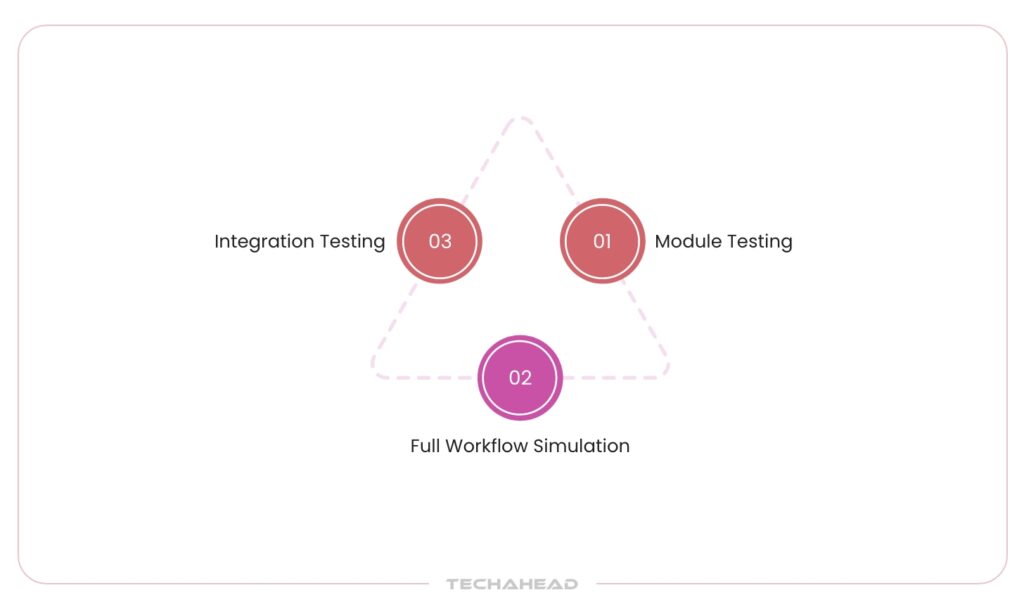
Agentic AI is made up of different parts like vector memory modules, logic engines, planning systems, and API callers. Testing them separately is helpful, but not enough; you also need to see how they work together.
- Module testing: Make sure each part (e.g., the retrieval system) performs its job correctly when tested on its own.
- Integration Testing: Check how well the parts communicate. Misalignment between modules often causes system errors.
- Full Workflow Simulation: Run the agent through real-life scenarios and monitor how it handles everything from user queries to API responses. This can expose issues like unnecessary repetitions or poor coordination between steps.
Adding Human Feedback to the Loop
Even with the best automated metrics, human feedback remains essential, especially when it comes to tone, empathy, and cultural context. In 2025, this is often augmented by RLAIF (Reinforcement Learning from AI Feedback).
- Detecting Bias: People can notice subtle stereotypes or unfair assumptions that automated tools often miss.
- Evaluating User Experience: In areas like customer service or healthcare, how the agent sounds (its tone and friendliness) matters just as much as its accuracy.
- Understanding Context: Humans can evaluate how well the agent adapts to business norms or local customs, which can’t always be captured through rules.
Practical Methods:
- Use annotated transcripts where users or experts highlight flaws or give scores.
- Run A/B tests where different versions of the agent are tested with users to find the best one.
- Let the agent escalate complex issues to a human, and record when and why this happens to retrain the model later.
Measuring Impact Through Experimentation
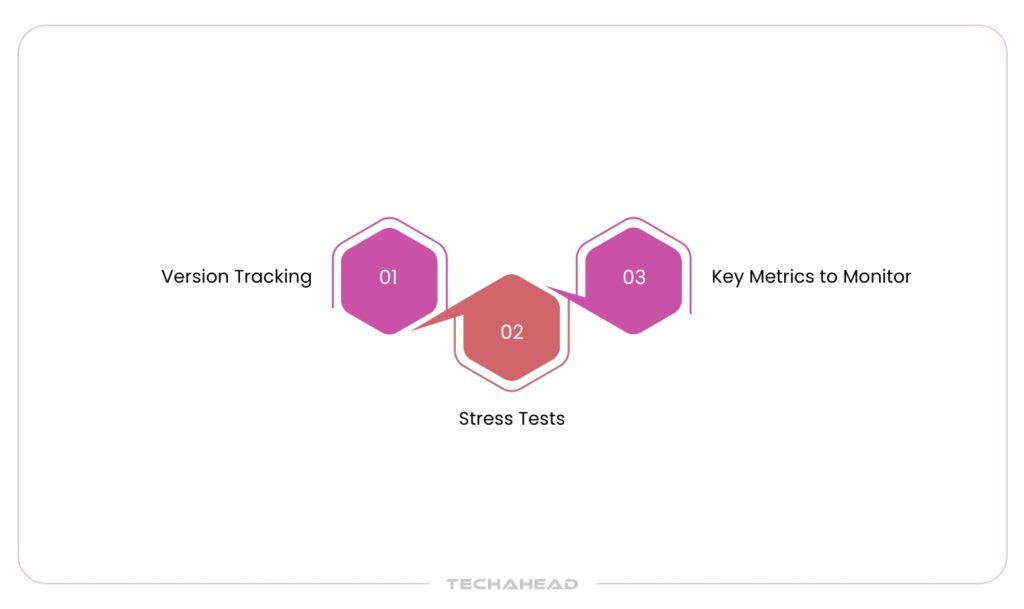
As your AI agent evolves, it does so by changing prompts, adding vector memory, or updating the model. It’s important to measure if the changes actually help using controlled experiments.
- Version Tracking: Keep older versions active for comparison. Send a small amount of user traffic to new versions and compare outcomes.
- Shadow Testing & Canary Deployments: Instead of immediate full rollout, run new versions in “shadow mode” (processing real traffic without showing answers to users) or release to a small % of users.
- Key Metrics to Monitor: Changes in THE, MCR, speed, customer satisfaction, and error rates are important indicators.
- Stress Tests: Don’t just test under normal conditions. Make sure performance hasn’t declined in unusual or high-pressure situations (e.g., during DDoS-like traffic spikes).
Improving with Fine-tuning and Prompt Engineering
You don’t need to rebuild your entire AI system to improve it. Techniques like PEFT (Parameter-Efficient Fine-Tuning) and prompt optimization offer more flexible and cost-effective ways to upgrade your agent’s behavior.
- Fine-tuning:
- Use specific data from your domain, like medical records or legal documents, to teach SLMs (Small Language Models) how to handle specialized tasks better at a lower cost
- Apply LoRA (Low-Rank Adaptation) to update in small cycles so each new challenge or mistake is addressed over time without retraining the whole model.
- Prompt Engineering:
- Even small changes in instructions can have a huge impact on the agent’s output.
- Utilize frameworks like DSPy (Declarative Self-improving Language Programs) to programmatically optimize prompts to find what works best for accurate, helpful, and consistent responses.
Real-Time Safety Controls
Despite rigorous testing, unexpected inputs and edge cases will still occur in live environments. That’s why real-time guardrails are essential to prevent damage before it happens.
- Policy enforcement on the fly: If the agent tries to take an action that breaks company rules, like revealing private info or using an unapproved tool, it should be stopped immediately.
- Live Monitoring: Continuously watch how the agent behaves in real time to detect anything out of the ordinary, such as repeated errors or suspicious conversations, or jailbreak attempts.
- Escalation to Humans: For sensitive situations, the agent should know when to pause and hand over control to a human, ensuring critical decisions get the oversight they need.
Conclusion
As AI agents become more autonomous and are trusted with increasingly complex tasks, the need for a structured and well-rounded evaluation approach becomes absolutely critical.
By looking beyond just a single success metric and instead combining multiple indicators like accuracy, latency, cost, stability, and robustness, organizations gain a fuller picture of how well an agent actually performs in real-world conditions. Pairing automated evaluation methods with human insights helps uncover both technical flaws and subtle user experience issues that might otherwise go unnoticed.
As a trusted mobile app development company, we believe consistent evaluation enables continuous optimization. It helps maintain performance as the environment evolves, safeguards against bias or drift, and reinforces trust in the system’s outputs. In a world where AI agents are increasingly making decisions that impact people, products, and profits, robust evaluation is not just an option, it is a mandatory thing for a business.

FAQs
Why is agentic AI evaluation important?
Evaluating agentic AI is crucial because these systems are more complex than traditional chatbots or automation tools. They must be assessed not only on output quality but also on how they reason, use tools, maintain context, and adhere to user intent. Evaluation helps ensure compliance, manage risk, and improve user experience.
What metrics are used to evaluate Agentic AI?
Key metrics include:
– Task Adherence: Measures if the agent stays on topic and fulfills user requests.
– Tool Call Accuracy: Assesses whether the agent uses the correct tools or APIs to accomplish tasks.
– Intent Resolution: Evaluates how well the agent understands and resolves user intents.
– Context Relevance: Determines if retrieved information is relevant to the query.
– Faithfulness: Checks if generated answers are faithful to the retrieved context (without requiring ground truth).
– Answer Similarity: Compares generated answers to ground truth answers (where available).
– Efficiency and Scalability: Measures speed, resource usage, and ability to handle increased workloads.
How is agentic AI evaluation different from traditional AI evaluation?
Traditional AI evaluation often focuses on accuracy, precision, recall, and F1-score for classification or regression tasks. Agentic AI evaluation must also assess reasoning, tool use, context management, and multi-step task execution because agentic systems are more autonomous and dynamic.
What are some common challenges in agentic AI evaluation?
– Complexity of multi-step workflows
– Difficulty in defining ground truth for open-ended tasks
– Ensuring explainability and transparency of agent decisions
– Managing runtime costs and infrastructure scaling
Can agentic AI evaluation help with regulatory compliance?
Yes, agentic AI evaluation modules often include features to help organizations manage regulatory compliance risks by tracking performance, ensuring transparency, and documenting decision-making processes.


